USING FINITE AUTOMATA TO REPRESENT MENTAL MODELS
A Thesis
Presented to
the Faculty of the Department of
Psychology
San Jose State University
In Partial Fulfillment
of the Requirements for the
Degree
Master of Arts
by
Maria Elena Romera
August 2000
© 2000
Maria Elena Romera
ALL RIGHTS RESERVED
ABSTRACT
The element lacking from past Human-Computer Interaction research is a method for systematically comparing a user's mental model to the way the machine actually works. The formal language of automata was used to represent both a device and students' mental models of it. Mental models were elicited during an interview with two parts. The first part consisted of a spontaneous description. The second part consisted of structured questions used to confirm what was said in the description, and uncover any further knowledge. Student models were compared to the model of the device to find missing or incorrect information. Participants were also tested with a compound task and true-false and multiple-choice problems to see if the mental model predicted task performance. The more similar the student's model was to model of the device, the better their performance. This methodology holds promise for examining the mental model of any system.
INTRODUCTION
The study of human learning and knowledge representation impacts not only the fields of developmental and cognitive psychology, but engineering as well. Whenever a system contains human-machine interaction, the successful implementation of the system depends upon taking human characteristics into account. Ergonomics, or physical characteristics, are regularly considered, but psychological characteristics are more difficult to define, much less measure. Because humans use "mental models" to describe, explain, and predict system states (Rouse & Morris, 1986), the mental model approach is taken for examining user knowledge of a device. The notion is that with the proper knowledge of the device, the user may effectively operate it. By examining the mental model, insights that affect design may be obtained. This paper hopes to contribute to the methods available for incorporating information about the user into design.
An Overview of Mental Models
Johnson-Laird (1980) defines a mental model as an internal representation of the world. Norman (1983) discusses mental models in an applied sense, defining them as the naturally evolving models that people formulate of a target system through interaction with it. He identifies four related models. According to Norman, the target system is that which exists in the world, the actual machine. The conceptual model is a representation of the target system created by teachers, designers, scientists, or engineers that is accurate, consistent, and complete. The mental model is the knowledge, beliefs, and confidence about the validity of the knowledge the human user has of the target system. Finally, the scientist's conceptualization is the model created by scientists that is meant to represent the user's mental model. Figure 1 illustrates the relationship between these models. The conceptual model is sometimes referred to as a machine or device model. In Kieras and Bovair (1984), what is called the mental model is really a conceptual model that the researchers aimed to have the participants acquire. Degani and Heymann (2000) use the term user model to describe the information provided to the user in training and user manuals. Kellogg and Breen (1990) use the term system model to refer to a model created from the information in the user manual, but as will be shown later, the information in the manual is not always an accurate or complete description of the machine.

In this paper, the information in the user manual is called the documentation model. An ideal model is defined as the knowledge that a person should have in order to use the system efficiently and effectively. Mental model is used to mean both the knowledge in the human's mind and the scientist's conceptualization of that knowledge, because a conceptualization is the best the researcher can ever come to the real thing. As Rouse and Morris (1986) wrote, "..the 'black box' of human mental models will never be completely transparent". Mental models can be thought of as a combination of declarative and procedural knowledge and how they interact to guide behavior. Mental models can be looked at in terms of how they are acquired, how they are represented, and how they can be measured.
Mental models are acquired through interaction with the environment, as a consequence of learning. Learning may occur through observation, instruction, or training (Van Lehn, 1996). In the absence of instruction, learning can also originate with problem solving (Anderson, 1995). This may be pure trial and error, or problem solving through the use of analogy. Once acquired, the question of how mental models are represented is widely debated. There is disagreement over whether knowledge is represented as images, as propositions, or some combination of both (see Johnson-Laird, 1980). This also brings into the discussion the subject of human memory and how it is organized. The knowledge stored in memory is generally divided into two types, conceptual (declarative) knowledge of what things are, and procedural knowledge of how things work. Mental model studies tend to examine one or the other (see below), but both types of knowledge are important to performing most tasks. The processes of both learning and representing knowledge are problematical to study because they occur within the "black box", the human mind.
Related to the questions of learning and representation is how to measure and describe mental models. Unfortunately, there is no way to look into the mind and observe the knowledge a person actually has, but there are many methodologies for getting at this knowledge. Cooke and Rowe (1994) make this point nicely in saying, "...the process of measuring a mental model is one of constructing that model based on data generated by a subject, not one of extracting the mental model from the head of the subject". They also state that there is no single best measure of a mental model; the validity of the model will depend on how well it predicts the criterion of interest. Thus, each measure will get at some aspect of the knowledge.
Some studies try to elicit mental models through measures such as verbal protocols, task performance, action sequences, reaction time, accuracy (or errors), interviews, teach back, and troubleshooting (Kieras & Bovair, 1984; Cooke & Rowe, 1994; Mark & Greer, 1995; Sasse, 1997). A few studies have sought to examine mental models through the use of multidimensional scaling (MDS) and trajectory mapping (TM) (Lokuge et al, 1996), or Pathfinder Networks (PFNETs) (Kellogg & Breen, 1990; Cooke, 1990). In the existing literature on mental models, it is often the case that knowledge is elicited and examined in pieces. Procedural knowledge studies tend not to model the knowledge per se, but merely test it, to measure performance on a task (e.g., Kieras & Bovair, 1984). Declarative knowledge studies model that type of knowledge with methods such as Pathfinder networks, but may completely neglect to examine procedural knowledge (e.g., Kellogg & Breen, 1990). Studies that model both types of knowledge tend to be simulation studies using computer programs (Kieras, 1990)-- which, admittedly, may or may not reflect true user knowledge or behavior.
The approach taken here is holistic and attempts to elicit and model both declarative and procedural knowledge from the user. While one goal is to complete a task, which is procedural, the user's declarative knowledge is important in being able to generate procedures to accomplish the task (Mark & Greer, 1995). The idea behind the process is to examine the mental model as completely as possible and then inform design. The method described in this paper is not meant for studying a topic such as students' knowledge of physics (diSessa, 1983), but specifically for knowledge of a device.
Comparing the Mental Model to the Machine
Certainly, it is interesting in and of itself to try to understand how the human mind learns, stores, and utilizes information in daily activities. But it is also important for designing systems, in order to predict and avoid breakdowns in the human-machine interaction. Because this study attempts to devise a methodology for examining mental models that will ultimately aid design, it would be helpful if the mental model could be expressed in a language that made it more easily comparable to the actual working of the machine. By making this comparison, missing and incorrect knowledge about the machine could be pinpointed and steps could be taken to fix it through training, documentation, procedures, or a redesign of the machine. The language of finite automata is a well-known formal language in the computer science community and is already used to model machines. Because of its utility and common usage in specifying, designing, and modeling devices and computer code, finite automata was chosen as the language to represent both the conceptual and mental models.
It is not necessarily proposed that the mind represents knowledge like a finite state machine; it is suggested that this is one of many methods that can be used to represent knowledge. Any mental model representation will always be the scientist's conceptualization rather than the true mental model. Previous studies have paved the way for representing the conceptual and mental models as finite automata. de Kleer and Brown (1981) alluded to the possibility of representing the mental model in finite automata by speaking of knowledge as a set of states and causally related events. Pathfinder networks have been used as the common language for comparing the user and system models (Kellogg and Breen, 1990), but have addressed only declarative knowledge. Finite state machines have been used before to represent the mental model, as is discussed below. The advantage of using finite automata is that the representation of the user's mental model can be easily compared to the conceptual model in terms of the states and transitions. The Statechart representations can be graphically compared. It is expected that there will be differences between the conceptual and mental models, and generally speaking, they should reflect the user's level of experience and knowledge about the system.
Past Studies
Other work has been done using finite automata in relation to mental models. Rushby (1999) represents both machine and mental models as finite state machines in order to use a formal method called model checking to see where the two diverge. The "mental model" in his work is suggested by human factors experts or derived from training materials rather than actually elicited from a human user. Thus, the process is a verification of the documentation model rather than an examination of the mental model. The present research is similar to Rushby's work in making a comparison between models, but differs by attempting to elicit the user's mental model rather than creating one.
Buchner and Funke (1993) used finite automata as dynamic task environments in testing the utility of an external memory aid. They note that the formal language of automata not only suggests assumptions about the mental representation of a discrete system, but also about systematic and appropriate diagnostic procedures. For example, in a state transition diagram, knowledge can be examined in terms of a state-transition-state triplet. It can thus be tested by asking what state occurs given a certain state and transition, or what transition connects two given states. A similar method of questioning was used by Salter (1986) in his survey on mental models of economic trends; questions were phrased in the form, "If X changes in this direction, what will be the effect on Y?" Buchner and Funke also discuss the possibility of state-transition associations clumping or forming chains (i.e., a series of associated transitions) as the user learns more about the machine. This can probably be related to the notion of acquiring automaticity (Logan, 1988), with a practiced user executing a series of instances in the associated chain.
Statecharts
The problem that Buchner and Funke note is that as systems become more complex, the number of states, transitions, and their combinations can become unmanageable. The exponentially growing multitude of states, or "state explosion problem", can be mitigated by using Statecharts (Harel, 1987). Statecharts are a visual formalism for describing finite state systems, with the added features of hierarchy, orthogonality, and broadcast-communication. With these extensions it is possible to show superstates and substates, independence between states (concurrency), and the events that occur as the result of a transition between states. This allows the same information to be shown much clearer graphically, even though the system complexity remains constant.
Statecharts were created with the intention of modeling complex systems. They are used to specify, analyze, and generate code for these systems. One way they are extremely useful is in a formal methods analysis for discovering design flaws in which the system can enter an illegal state, to predict problems in system performance. This study seeks to answer the question of whether modeling user knowledge in Statecharts can help predict problems in user performance. By representing the mental model in the same language as the conceptual model, the two can be compared and errors in the user's mental model can be pinpointed.
Objectives
The long-range goal of this study is to facilitate good design by providing methods to incorporate information about the user. The approach is through the comparison of the conceptual and mental models, using the language of finite automata to represent each model. With this preparation, there were two specific questions that the researcher aimed to answer:
- Can mental models be represented using finite automata?
- Will such a representation enable the prediction of errors?
The methods of eliciting the mental model were designed to try to extract as much knowledge as possible, both procedural and declarative. The Statecharts of the clock and the participants were compared to highlight differences, and participants with fewer differences were expected to show better performance during testing.
Methods
The Modeling Process: Travel Alarm Clock
The system modeled was a travel alarm clock. The modeling process began with learning to use the clock. The system was first described in natural language, noting interface components and their functions. A graphical depiction of the interface is shown in Figure 2.
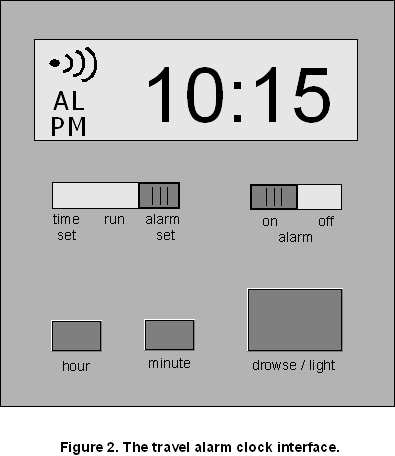
A system decomposition was then performed, with the purpose of separating device behaviors from how they are implemented; the clock was broken down in terms of modes, functions, components, requirements, input, and output. Modes were put into a matrix and tested to see which combinations were possible and which were not. State transition diagrams were used to describe the transitions between different modes and states within those modes. State diagrams were also used to examine the procedure that would be used to set the time, set and arm the alarm, and disarm the alarm. All of these descriptions and analyses were used to obtain a good understanding of the behavior of the clock so that it could then be represented as a Statechart (Figure 3).
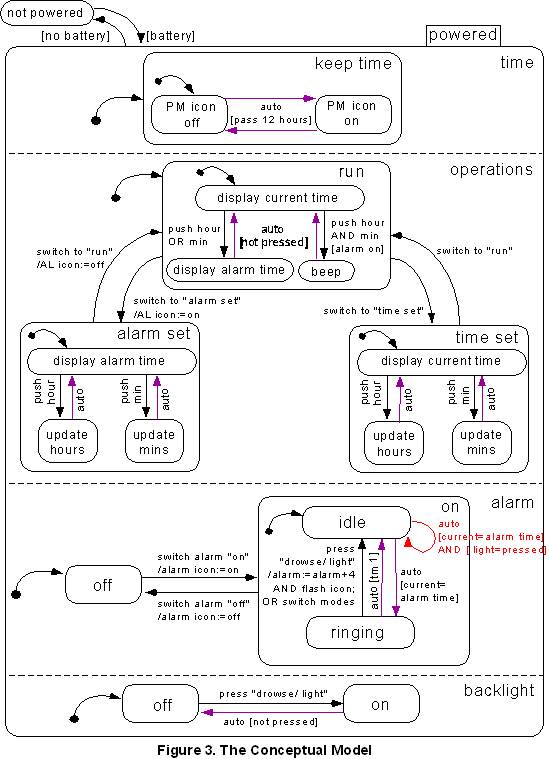
The Statechart was tested by trying all possible combinations of modes and user actions, to be sure that there was no behavior missing; anything that is possible is represented. There are four concurrent processes operating in the clock as long as it is powered: time (continuously running), operations (run, alarm set, time set), alarm (on, off), and backlight (on, off). The clock is powered by battery. There is an indicator light, "PM", which is on during the p.m. and off during the a.m. hours (a.m. is signaled by the absence of the indicator). The default operation is "run", which displays the current time and allows the user to check the alarm time or alarm tone by using the hour and minute buttons. The time is set by moving the mode switch to "time set" and pressing the hour button and minute button to reach the desired time, while minding that the PM light is indicating the correct hour. The alarm is set analogously by moving the mode switch to "alarm set", and this mode is indicated by the "AL" light on the display.
The alarm can be switched on or off; "on" mode is indicated by an icon resembling sound waves. If the alarm is armed, or set to the "on" position, it will ring when the current time reaches the alarm time, with one exception: if the light is being pressed simultaneously to this event, the alarm will not ring. This is a dangerous transition because unlike the normal drowse function that resets the alarm time, the alarm will not ring until 24 hours later.
When ringing, the alarm will timeout after one minute. If the alarm is ringing and the drowse button is pushed, the alarm will be reset for four minutes later, and the alarm "on" icon will flash. The alarm can also be made to stop ringing by moving the mode switch. The light is simply off unless the button is pressed to turn it on, but because the button doubles as the drowse there is an interaction with that function (mentioned above). Transitions in the model that are automatic, or uncommanded by the user, are shown in purple. The automatic transition that represents the interaction between the light and snooze functions is shown in red.
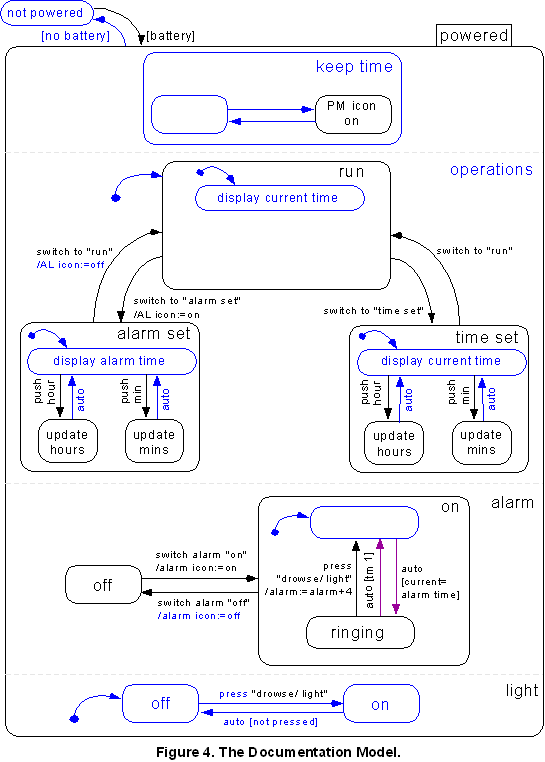
Another Statechart was created from the documentation, a one-page set of instructions about the clock found on the back of the packaging. This Statechart is called the documentation model (Figure 4). The instructions give a simplified model of the clock, leaving out many details. Because some omitted details are important for preventing errors this model is not ideal. One important detail left out is that the user is not told that a.m. is represented by the absence of the PM light. The documentation model also does not give any information about concurrency. For this model, states and transitions that are only implied and not explicitly described are represented in blue. For example, the instructions say that the AL light comes on when the mode switch is moved to "alarm set", but do not explicitly say that it goes back off when the switch is returned to "run". Therefore, the AL light going off is implied (blue) on the transition between "alarm set" and "run".
Pilot Study
A pilot study was conducted with two participants, who were undergraduate psychology students participating for extra credit. The procedure for testing these participants was the same as will be described below, except that they did not receive the true-false and multiple-choice problems. These problems were added to the procedure in order to address misconceptions that were found in the pilot participants' mental models and were expected to be in subsequent participants' mental models. Misconceptions had to do with concurrency and the display icons. They both believed that the time stopped running during "time set", and neither made any mention of the AL or alarm-on icons. Participant 1 thought that the alarm couldn't ring when the clock was in "time set" mode. Participant 2 thought the alarm couldn't ring in "alarm set" mode, and believed there was an AM light. Because the clock is a simple device, their task performance showed no errors despite the fact that their understanding of the clock had some errors. The structured questions were also refined as a result of the interviews with these participants; questions were clarified or added.
Main Study
Participants were 8 undergraduate psychology students who participated for course credit. They were aged 18 to 30. English was not the native language of participants 2, 4 and 5, and participant 4 expressed some concern about English comprehension.
Participants were tested individually. Prior to beginning, the participants read the instructions for the study. For each part of the study, they were given verbal instructions and then given the chance to ask questions to clarify their task. The study was divided into four parts, and the participants were given the chance to take a break in the middle of the session, but none opted to do so. The entire session took about 45 minutes. The session was audiotaped to ensure correct recording of all verbal answers (verbal protocol), except for the true-false and multiple-choice problems which were administered with pencil and paper. For the first part, the participants were instructed to read the directions (the product documentation), look at the clock, and decide how they thought it works. They then described how the clock works to the experimenter. Participants were encouraged to interact with the clock as they described it. The description ended when they felt they had described as much as they could about the clock.
The second part consisted of the researcher asking structured questions in order to clarify any concepts that were implied in the first session and to uncover any knowledge the participant may not have mentioned in the first session. The list of questions can be found in Appendix A. Each question was written to address a specific element of the Statechart model, such as a transition between states, without giving the participant any information that they had not already explicitly described. The questions were phrased using a state-transition-state triplet in order to facilitate building a Statechart of the mental model.
The third part was a compound task to demonstrate use of the clock. Participants were instructed to take the appropriate action given the following scenario: "You have just arrived here in California on a flight from another time zone. You need to adjust your clock to local time. In addition, you want to use the clock to time a two-minute egg because they didn't serve food on the flight. When the alarm rings you should disarm it." The task was considered as consisting of three parts: setting the time, setting and arming the alarm, and turning off the alarm. Participants were asked to verbalize what they were doing as they did it so that action sequences could be recorded. The task was considered complete when the participant accomplished the third part and turned off the alarm. Following one of several correct action sequences would lead to task completion.
The final part of the session was a set of 10 true-false and 10 multiple-choice problems administered with paper and pencil (Appendix B). These problems were designed to test misconceptions found in the pilot study. Examples are knowledge of which icon signals that the clock is in "alarm set" mode, and whether the time is kept while the clock is in "time set" mode.
After collecting the data, the researcher first constructed an individual Statechart from the spontaneous description to represent the knowledge the participant expressed or implied. Information about the clock the participant made explicit was represented in black or purple (recall that purple represents automatic transitions), while information only implied was represented in blue. The answers to the structured questions were used to complete the Statechart of the participant's mental model (the scientist's conceptualization). Statecharts were assigned scores based on the number of transitions present, as compared with the conceptual model. A conservative rating counted only explicit transitions with the correct conditions and triggered events. A liberal rating counted explicit transitions that were present even if the condition for making that transition was incorrect or absent. The participants' Statecharts (scores and missing or incorrect information) were used as a baseline for predicting performance on the task and the multiple-choice and true-false questions.
Results
The audiotapes of the interviews were transcribed. Statements were interpreted as what was explicit and implied. Information from the spontaneous descriptions and answers to structured questions was used to make the participant's Statecharts. Figures 5 through 12 (click to open new window for each figure: 5, 6, 7, 8, 9, 10, 11, 12) show the scientist's conceptualization of each participant's mental model. Naturally, each model was influenced by the instructions, and resembles the documentation model to some degree. The mistakes generally had to do with things the documentation model did not describe, but there was also confusion about the icons on the display. For example, participants 2 and 4 show confusion between the alarm "on" and "alarm set" ("AL") icons. Participant 5 left quite a bit of information out of descriptions, even when asked direct questions. This made predictions difficult for that participant. The statecharts for participants 1, 2, 7, and 8 may appear drastically different from the conceptual model, but they are simply rearranged to show concurrency, or the lack of it in these cases. For example, states were regrouped to show that participant 2 said that the clock did not keep time when the clock was in "time set".
The spontaneous descriptions and answers to the structured questions were also used to make predictions about performance. The predictions were compared to the results of the task performance and the true-false/multiple-choice (TF/MC) questions. In terms of the task, it was assumed that all participants would complete it. Table 1 shows that the only task predictions made from the Statecharts were that participants 1, 5, 6 and 7 might forget to move the mode switch back to "run", because they left that out of their verbal description of the procedure during the interview. During the task they did not forget this step.
Table 1 Comparison of Statechart Predictions to Task Results by Subject ________________________________________________________________________________ Subject Prediction Task Result ________________________________________________________________________________ 1 May forget to move Complete Did not forget. switch back to "run". 2 No errors predicted. Complete No errors. 3 No errors predicted. Complete No errors. 4 No errors predicted. Incomplete Forgot to check the hour, set wrong alarm time. 5 May forget to move Incomplete Forgot to set the current switch back to "run". time (switch back to run). 6 May forget to move Complete Did not forget. switch back to "run". 7 May forget to move Complete Did not forget. switch back to "run". 8 No errors predicted. Incomplete Forgot to check PM light, set time a.m. and alarm p.m.
Participants 1, 2, 3, 6 and 7 were able to correctly complete the task. Participants 4, 5 and 8 did not complete the task because they each made an error that precluded the alarm from ringing, and so could not make the final step of turning it off. The procedure followed by these participants can be examined in Figure 13. Participant 4 correctly set the current time, but when setting the alarm only advanced the minutes forward by two and neglected to ensure the hour was correct (it was not). Participant 5 completely forgot to set the current time (actual time was 11:46am, the clock read 3:46pm). This participant began by moving the alarm switch to "on", and then setting the alarm to the current time plus two minutes (11:48am). Participant 8 neglected to check the PM light, and presumably accidentally set the time to 3 a.m. and the alarm to 3 p.m.
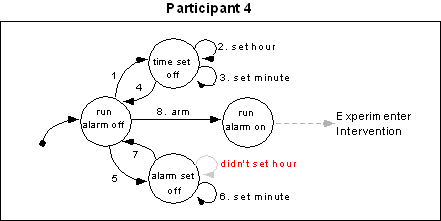
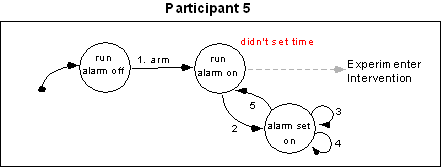
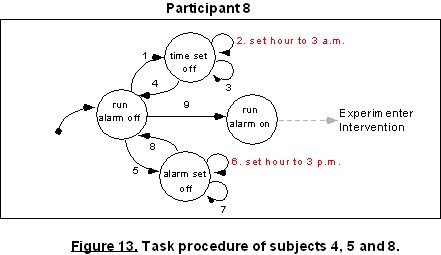
Table 2 shows the comparison of the predictions made from the Statecharts to the results for the true-false/multiple-choice questions. Out of 26 predictions, 24 were correct. The predictions that were wrong stemmed from the fact that during the structured questions participants 2 and 8 answered a question incorrectly, but correctly answered the same question in the TF/MC problems. There were 12 TF/MC mistakes not predicted. Nine of the mistakes not predicted were errors the participants made despite the fact they had answered the same thing correctly during the structured questions. The three remaining errors not predicted were due to three participants each making a mistake on a TF/MC question about the clock cycling from 59 to 00 minutes, which was never probed in the structured questions and so could not be predicted. There were also errors that participants made in the interviews that do not appear in Table 2 because there was no problem in the TF/MC questions to test it.
Table 2 Comparison of Statechart Predictions to True-false/Multiple-choice Results by Subject _______________________________________________________________________________________ Subject Prediction Result _______________________________________________________________________________________ 1 1. Believes there is an AM light. 1. Believes there is an AM light. 2. Thinks time stops in time set. 2. Thinks time stops in time set. 3. Thinks alarm can't ring in time set. 3. Thinks alarm can't ring in time set. 4. Doesn't know how to check alarm 4. Doesn't know how to check alarm time in run mode. time in run mode. 5. Thinks alarm can't ring in alarm set. 2 1. Confuses AL and alarm-on icons. 1. Confused, answers inconsistently. 2. Confuses alarm-on and alarm set. 2. Associates alarm-on icon with alarm set. 3. Thinks time stops in time set. 3. Correctly answered time continues in time set. 4. Thinks alarm can't ring in alarm set. 4. Thinks alarm can't ring in alarm set. 5. Doesn't know how to check alarm 5. Doesn't know how to check alarm time in run mode. time in run mode. 6. Answered there is an AM light. 7. Doesn't know minutes cycle from 59-00. 3 1. Doesn't know how to check alarm 1. Doesn't know how to check alarm time in run mode. time in run mode. 4 1. Believes there is an AM light. 1. Believes there is an AM light. 2. Confuses AL and alarm-on icons. 2. Confused, answers inconsistently. 3. Doesn't know how to check alarm 3. Doesn't know how to check alarm time in run mode. time in run mode. 4. Answered alarm can't ring in alarm set. 5 1. May not know AL or alarm-on icons. 1. Confused, answers inconsistently. 2. May think there is an AM light. 2. Answered there is an AM light. 3. Doesn't know how to check alarm 3. Doesn't know how to check alarm time in run mode. time in run mode. 4. Doesn't know the display in time set. 4. Answers inconsistently. 6 1. Confuses whether there is an AM light. 1. Answers inconsistently. 2. Knows how to check the alarm time 2. Answered one correct, one in run mode. incorrect. 3. Answered time stops in time set. 4. Answered alarm can't ring in time set. 5. Answered alarm can't ring in alarm set. 6. Answered inconsistently about minutes cycling 59-00. 7 1. Doesn't know how to check alarm 1. Doesn't know how to check alarm time in run mode. time in run mode. 2. Thinks alarm can't ring in time set. 2. Thinks alarm can't ring in time set. 3. Thinks alarm can't ring in alarm set. 3. Thinks alarm can't ring in alarm set. 4. Answered time stops in time set. 8 1. Thinks time stops in time set. 1. Thinks time stops in time set. 2. Thinks alarm can't ring in time set. 2. Thinks alarm can't ring in time set. 3. Thinks alarm can't ring in alarm set. 3. Correctly answered alarm can ring in alarm set. 4. Doesn't know how to check alarm 4. Doesn't know how to check alarm time in run mode. time in run mode. 5. Answered inconsistently about AM light. 6. Answered inconsistently about minutes cycling 59-00. 7. Doesn't understand AL light.
The method of scoring the Statecharts resulted in a total possible score of 29, with the participants' scores ranging from 8-15 on the conservative rating. Table 3 shows the liberal and conservative rating for each participant's Statechart along with their scores from the true-false and multiple-choice questions. The total possible score was 100 points for both the true-false and the multiple-choice problems. Participants did better on the true-false questions (M = 78.8, SD = 9.9) than on the multiple-choice questions (M = 52.5, SD = 17.5). The conservative Statechart scores appeared to be correlated with the average TF/MC score, but did not reach statistical significance using the entire data set (r = .52, df = 6, n.s.).
Table 3 Comparison of Statechart to True-false/Multiple-choice (TF/MC) Scores by Subject ____________________________________________________________________________________ Subject Statechart Score TF/MC Scores _____________________________ _______________________________________ Liberal Conservative Average TF MC ____________________________________________________________________________________ 1 13 11 60 80 40 2 15 10 50 60 40 3 17 15 90 90 90 4 16 13 55 70 40 5 11 8 65 80 50 6 16 14 70 80 60 7 15 13 75 90 60 8 15 14 60 80 40
Because there were participants who were non-native English speakers, and because the interview and testing processes were very verbal, there was concern that comprehension problems may have altered the data. The researcher suspected the data of participants who did not complete the task, so a post hoc criterion of task completion was set. This excluded participants 4, 5 and 8 from the analysis. Reevaluation of the data with the smaller sample showed a significant correlation between conservative Statechart scores and average TF/MC scores (r = .94, df = 3, p < .05). In the entire sample it appeared that the closer the mental model was to the conceptual model, the better the performance, and in the smaller sample that was indeed the case.
Discussion
The purpose of this study was primarily exploratory, asking two main questions: can human knowledge be represented in the formal language of automata? And will that representation give a good conceptualization of the mental model, thus allowing the prediction of errors? The answers to these questions are promising for utilizing this method in the future. Indeed, questions can be written to elicit knowledge in a state-transition-state format. The answers can be used to create a Statechart representing the mental model. A more complete conceptualization of the mental model could be achieved by tailoring questions to each individual, but then it must be noted that the procedure is not standardized. The interview data allowed for the prediction of many errors, and a more complete conceptualization should lead to better prediction. It should be possible to refine the processes of both the elicitation and the testing in the future. Overall, it did appear that the closer the mental model to the conceptual model, the better the performance.
Some errors could be predicted by comparing the documentation model to the conceptual model, because the instructions are an incomplete model of how the clock actually works. The documentation model does not describe concurrency or how a.m. is indicated (or not indicated, in this case), and participants did make errors on those items. Because the three participants that confused the alarm "on" and "alarm set" icons were not-native English speakers it is not clear whether their mistakes were due to a language problem, insufficient instructions, or a poor mental model. Language could also be a factor in why participants 4 and 5 failed to complete the task; however, they could plausibly be examples of a prospective memory failure (forgetting to do a future action). The researcher did not predict that anyone would fail to complete the task, but the errors that prevented task completion are plausible real world errors. It is possible that they knew what they were supposed to do and simply forgot a step, especially because they were able to verbalize the procedure for each step of the task in separate questions during the interview. The fact that participant 8, with no English difficulties, also failed to complete the task, points to fault in the instructions or design of the clock. Why some participants answered a question correctly at one point in the study and incorrectly at another may be due to the fact that they had just encountered the clock for the first time and their mental model was not concrete, but evolving.
In examining the errors, it may be useful to distinguish important errors from the unimportant ones. What is important will depend on what the user needs to know to accomplish her task efficiently and effectively, the ideal mental model. For the clock, the high-level goal is to wake up on time. Therefore, the user must know how to set the time and alarm, and arm and disarm the alarm. The participants who completed the task achieved this level of knowledge, so it would be tempting to say that any errors they made are unimportant. They did achieve the level of knowledge given by the documentation model, but in this case the documentation model is not ideal. Because there is at least one instance where the alarm could be accidentally disarmed (using the light at the precise moment the alarm time arrives), more information needs to be added to the documentation model, and thus to the user's mental model, to make it ideal. Alternatively, and perhaps the better route, the design of the clock could be changed so that this transition is not possible.
Using Statecharts overcomes the two fundamental problems with the study of mental models as described by Kellogg and Breen (1990): capturing the system model and comparing it to the mental model. They write, "without the definition of a system model, what the user should know and therefore what his mental model should contain are unknown...[second] is the difficulty of 'capturing' the user's mental model, particularly in a way that can be systematically compared with a system model". The conceptual model represented in this study as a Statechart fully describes the behavior of the clock. By representing both machine and mental model in the same language we can make a systematic comparison.
It is not necessarily the Statechart itself, but the process by which it is developed that gives the information necessary to make predictions about performance. Once the information is placed in a Statechart, each element can be thought of as a piece of knowledge. The transitions in the Statechart represent procedural knowledge, with each transition being some procedure followed by the user (commanded) or the machine (uncommanded or automatic). The states and other elements in the Statechart represent declarative knowledge. Even so, it is important to note that not all knowledge of the device will be represented in the Statechart. The Statechart only represents behavior, so participant comments such as "it is made of plastic" are not part of the model. It should also be noted that the procedure for scoring Statecharts used here was a first attempt to quantify them, and may require further development. There were also lessons learned regarding the interview and testing process:
- Development of the structured questions is a critical step that may take several iterations. If this study were to be repeated, the questions would undoubtedly be refined based on the data collected.
- Similar to the point above, the true-false and multiple-choice questions must be carefully designed. In this study there were separate problems that questioned the same transition, and some participants answered each differently.
- A criterion should be set a priori for the acceptable proficiency level or task performance that must be reached to include the data in the analysis if statistics are to be applied.
At present, the process of eliciting and representing mental models in this fashion is rewarding yet labor intensive, in terms of the interview process and the data analysis. Each individual's data must be analyzed separately and carefully. This could become prohibitive on a larger, more complex system. Computers may be able to help in this regard in future studies. For example, building a virtual interface and recording action sequences on computer would be a viable way to make data collection easier. However, the tradeoff would be the insight into the mental model that the researcher may acquire through direct interaction with the participant.
Another issue with this approach is that as the system becomes larger it may become impractical to probe the mental model on the full behavior of the machine, as was done here. To address this issue, a task analysis should be added to the equation, and an ideal mental model should be derived. Given the behavior of the machine and given the tasks the operator must perform on it, an intersection of necessary knowledge can be found. It may be necessary to look at different tasks separately in order to reduce the model into workable pieces. Even with the addition of task analysis, there are systems (i.e., complex cockpit automation) for which the full behavior is not exhaustively documented and is therefore difficult to describe, but that is a problem beyond the scope of this method. Although some systems may prove more challenging for the researcher to study, theoretically, this method can be used to look at the user's mental model for any system. The advantage of making a direct comparison between the conceptual and mental models, and making predictions based on the differences, is the potential to avoid problems in human-machine interaction before they happen.
References
Anderson, J.R. (1995). Cognitive psychology and its implications (4th ed.). New York: W.H. Freeman and Company.
Buchner, B. & Funke, J. (1993). Finite-state automata: Dynamic task environments in problem-solving research. The Quarterly Journal of Experimental Psychology, 46A(1), 83-118.
Cooke, N. J. (1990). Using Pathfinder as a knowledge elicitation tool: Link interpretation. In R. W. Schvaneveldt (Ed.), Pathfinder Associative Networks: Studies in Knowledge Organization. New Jersey: Ablex Publishing Corporation.
Cooke, N.J., & Rowe, A.L. (1994). Evaluating mental model elicitation methods. Proceedings of the Human Factors and Ergonomics Society 38th Annual Meeting. Nashville, Tennessee.
Degani, A. & Heymann, M. (2000). Pilot-autopilot interaction: A formal perspective. Eighth International Conference on Human-Computer Interaction in Aeronautics. Toulouse, France. September 27-29, 2000.
de Kleer, J. & Brown, J. S. (1981). Mental models of physical mechanisms and their acquisition. In J. R. Anderson (Ed.), Cognitive Skills and Their Acquisition. Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers.
diSessa, A. A. (1983). Phenomenology and the evolution of intuition. In D. Gentner & A. L. Stevens (Eds.), Mental Models. New Jersey: Lawrence Erlbaum Associates, Publishers.
Harel, D. (1987). Statecharts: a visual formalism for complex systems. Science of Computer Programming, 8, 231-274.
Johnson-Laird, P. (1980). Mental models in cognitive science. Cognitive Science, 4, 71-115.
Kellogg, W. A. & Breen, T. J. (1990). Using Pathfinder to evaluate user and system models. In R. W. Schvaneveldt (Ed.), Pathfinder Associative Networks: Studies in Knowledge Organization. New Jersey: Ablex Publishing Corporation.
Kieras, D. E. (1990). The role of cognitive simulation models in the development of advanced training and testing systems. In N. Frederiksen, R. Glaser, A. Lesgold, and M. G. Shafto (Eds.), Diagnostic Monitoring of Skill and Knowledge Acquisition. Hillsdale, New Jersey: Lawrence Earlbaum Associates, Publishers.
Kieras, D. E. & Bovair, S. (1984). The role of a mental model in learning to operate a device. Cognitive Science, 8, 255-273.
Logan, G. D. (1988). Toward an instance theory of automatization. Psychological Review, 95, 492-527.
Lokuge, I., Gilbert, S. A., & Richards, W. (1996). Structuring information with mental models: A tour of Boston. Paper presented at the CHI96 Conference on Human Factors in Computing Systems. April 13-18, 1996, Vancouver, British Columbia, Canada.
Mark, M. A. & Greer, J. E. (1995). The VCR tutor: Effective instruction for device operation. The Journal of The Learning Sciences, 4(2), 209-246.
Norman, D. (1983). Some observations on mental models. In D. Gentner & A. L. Stevens (Eds.), Mental Models. New Jersey: Lawrence Erlbaum Associates, Publishers.
Rouse, W. B. & Morris, N. M. (1986). On looking into the black box: Prospects and limits in the search for mental models. Psychological Bulletin, 100(3), 349-363.
Rushby, J. (1999). Using model checking to help discover mode confusions and other automation surprises. Presented at The 3rd Workshop on Human Error, Safety, and System Development (HESSD'99), Liege, Belgium, 7-8 June 1999.
Salter, W.J. (1986). Tacit Theories of Economics. A Dissertation Presented to the Faculty of the Graduate School of Yale University in Candidacy for the Degree of Doctor of Philosophy.
Sasse, M. A. (1997). Eliciting and Describing Users' Models of Computer Systems. A thesis submitted to the Faculty of Science of the University of Birmingham for the degree of Doctor of Philosophy (Computer Science). Birmingham, England.
Van Lehn, K. (1996). Cognitive skill acquisition. Annual Review Psychology, 47, 513-539.